Data Science/NLP
[NLP 개론] #1 언어모델의 발전, RNN부터 GPT-4까지
PM스터
2024. 2. 14. 00:56
반응형
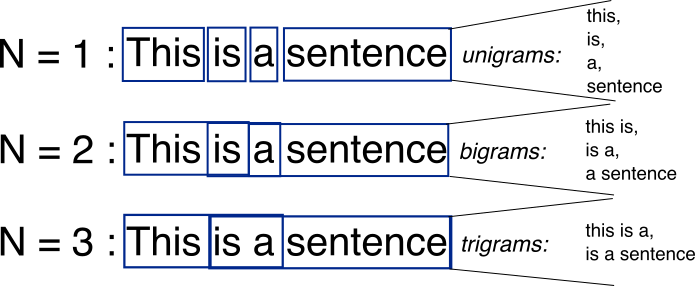
0. N-gram
- 정의: N-gram은 텍스트 데이터에서 N개의 연속적인 아이템(단어, 문자 등)의 시퀀스를 의미함. 주어진 시퀀스에서 다음 아이템을 예측하기 위해 이전 N-1개의 아이템을 사용함.
- 개발 목적: 언어 모델링과 텍스트의 확률적 속성을 분석하기 위해 사용됨. 주로 텍스트 데이터에서 패턴을 인식하고, 주어진 시퀀스에 이어질 가능성이 높은 아이템을 예측하는 데 활용됨.
- 장점: 구현이 간단하고 계산 비용이 낮으며, 작은 데이터셋으로도 효과적인 모델을 구축할 수 있음.
- 단점: 문맥의 장거리 의존성을 잡아내기 어려움. N의 크기가 커질수록 모델이 처리해야 할 가능한 시퀀스의 수가 기하급수적으로 증가하여, 데이터의 희소성(sparsity) 문제가 발생할 수 있음.
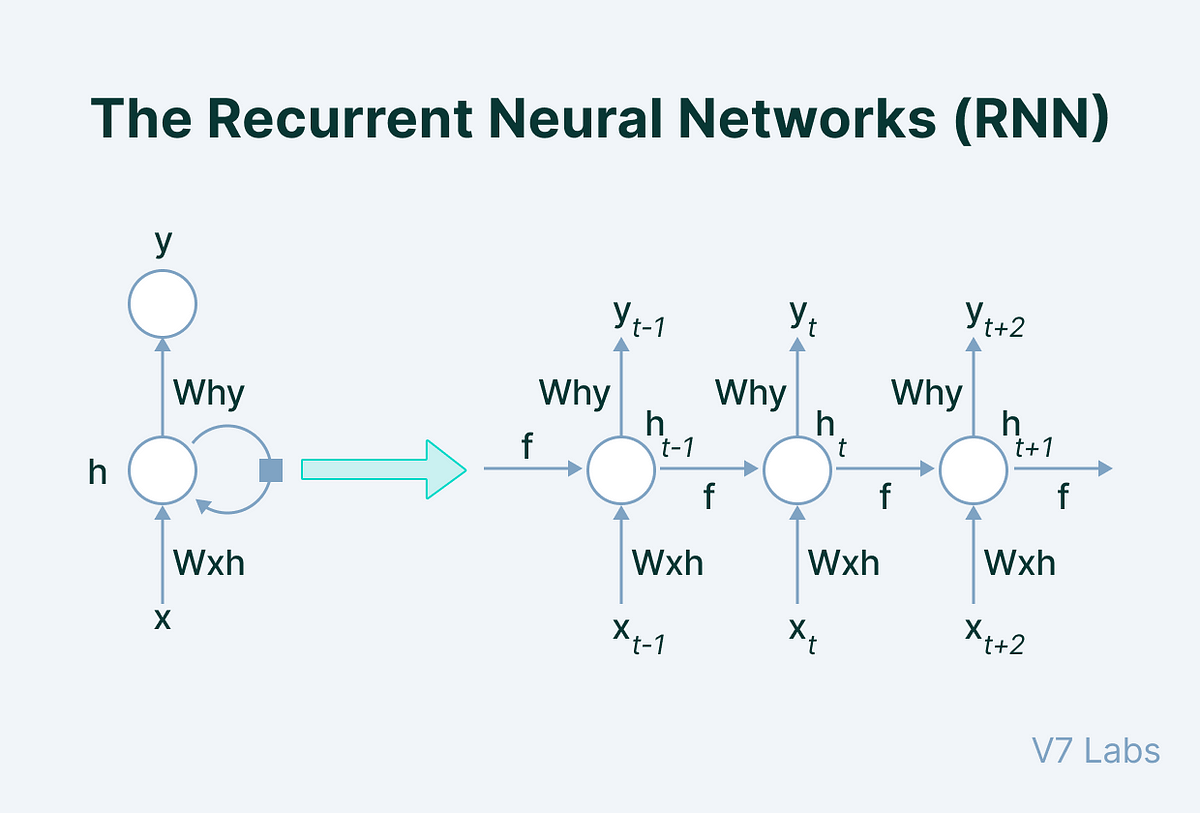
1. RNN (Recurrent Neural Network)
- 정의: RNN은 순차적 데이터 처리를 위해 고안된 신경망 구조로, 이전의 정보를 현재의 결정에 반영할 수 있도록 설계됨. 내부에 순환 구조(loop)를 가지고 있어, 시퀀스의 각 요소를 순차적으로 처리하면서 이전 단계의 정보를 기억할 수 있음.
- 개발 목적: 시퀀스 데이터(예: 텍스트, 시계열 데이터)를 처리하여, 시퀀스 내의 항목들 사이의 장기 의존성을 학습하기 위해 개발됨. 자연어 처리, 음성 인식, 시계열 예측 등 다양한 분야에서 활용됨.
- 장점: 시퀀스 데이터의 순서 정보를 유지하며 처리할 수 있어, 자연어 처리(NLP)와 같은 분야에서 유용하게 사용됨. 시간적으로 떨어져 있는 정보 간의 관계를 학습할 수 있는 능력이 있음.
- 단점: 장기 의존성 문제(long-term dependencies)로 인해, 긴 시퀀스를 처리할 때 성능이 저하될 수 있음. 이는 학습 과정에서 발생하는 기울기 소실(gradient vanishing) 또는 기울기 폭발(gradient exploding) 문제 때문임.
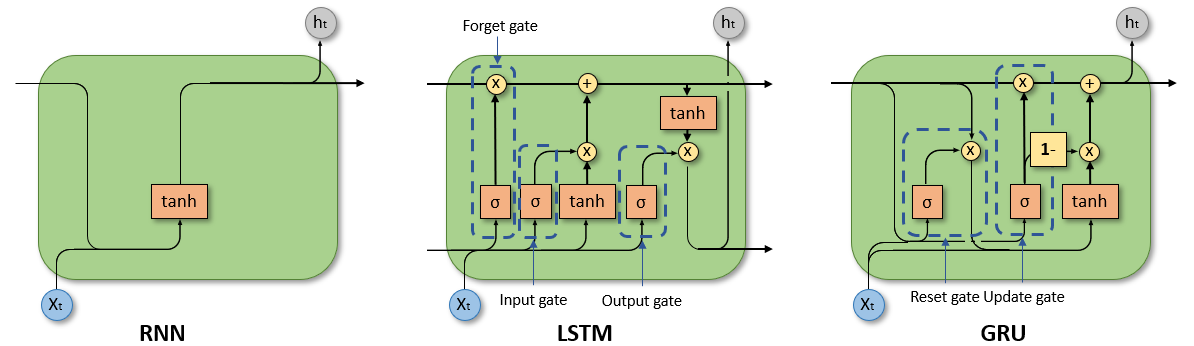
2. LSTM (Long Short-Term Memory)
- 정의: LSTM은 RNN의 한 종류로서, 장기 의존성 문제를 해결하기 위해 고안된 신경망 구조로, 게이트 메커니즘을 통해 정보를 장기간 저장하거나 삭제할 수 있는 능력을 갖춤.
- 개발 목적: 시퀀스 데이터를 처리할 때 RNN이 직면하는 장기 의존성 문제를 해결하려는 목적으로 개발되었으며, 이를 통해 보다 복잡한 시퀀스 패턴을 학습할 수 있도록 설계됨.
- 장점: 장기 의존성을 효과적으로 관리할 수 있어, 긴 시퀀스 데이터를 처리하는 데 있어서 RNN에 비해 우수한 성능을 보임. 이로 인해 자연어 처리, 음성 인식 등 다양한 분야에서 널리 사용됨.
- 단점: RNN에 비해 모델의 복잡성이 증가하여, 학습 시간이 길어지고 계산 비용이 더 많이 듦.
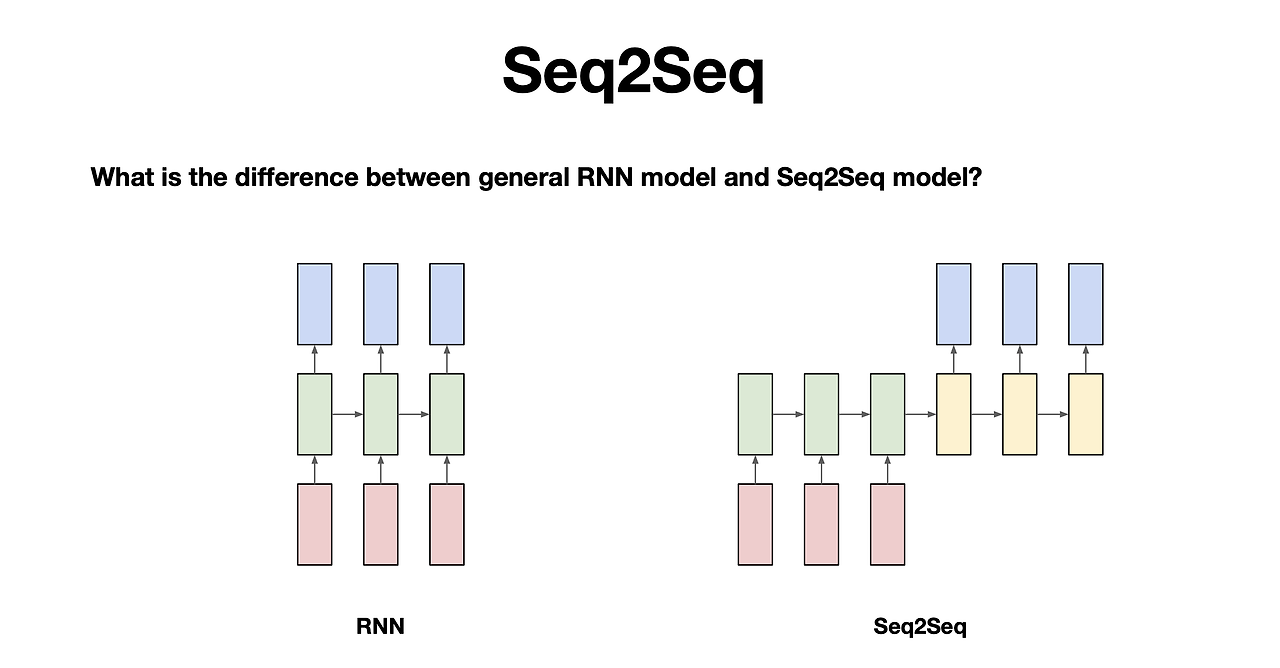
3. Seq2Seq (Sequence to Sequence)
- 정의: Seq2Seq는 입력 시퀀스를 받아 출력 시퀀스를 생성하는 모델로, 주로 인코더와 디코더 두 부분으로 구성되어 있음. 인코더는 입력 시퀀스를 고정된 길이의 벡터로 변환하고, 디코더는 이 벡터를 사용해 출력 시퀀스를 생성함.
- 개발 목적: 기계 번역, 자동 요약, 대화 시스템 등 입력과 출력이 모두 시퀀스 형태인 문제를 해결하기 위해 개발됨. 이를 통해 다양한 길이의 시퀀스를 효과적으로 처리할 수 있음.
- 장점: 다양한 길이의 입력과 출력 시퀀스를 처리할 수 있으며, 인코더-디코더 구조를 통해 복잡한 시퀀스 변환 작업을 수행할 수 있음.
- 단점: 입력 시퀀스가 매우 길 경우, 인코더에서 생성된 고정 길이의 벡터가 모든 필요 정보를 담기 어려울 수 있으며, 이는 디코더의 출력에 영향을 미칠 수 있음.
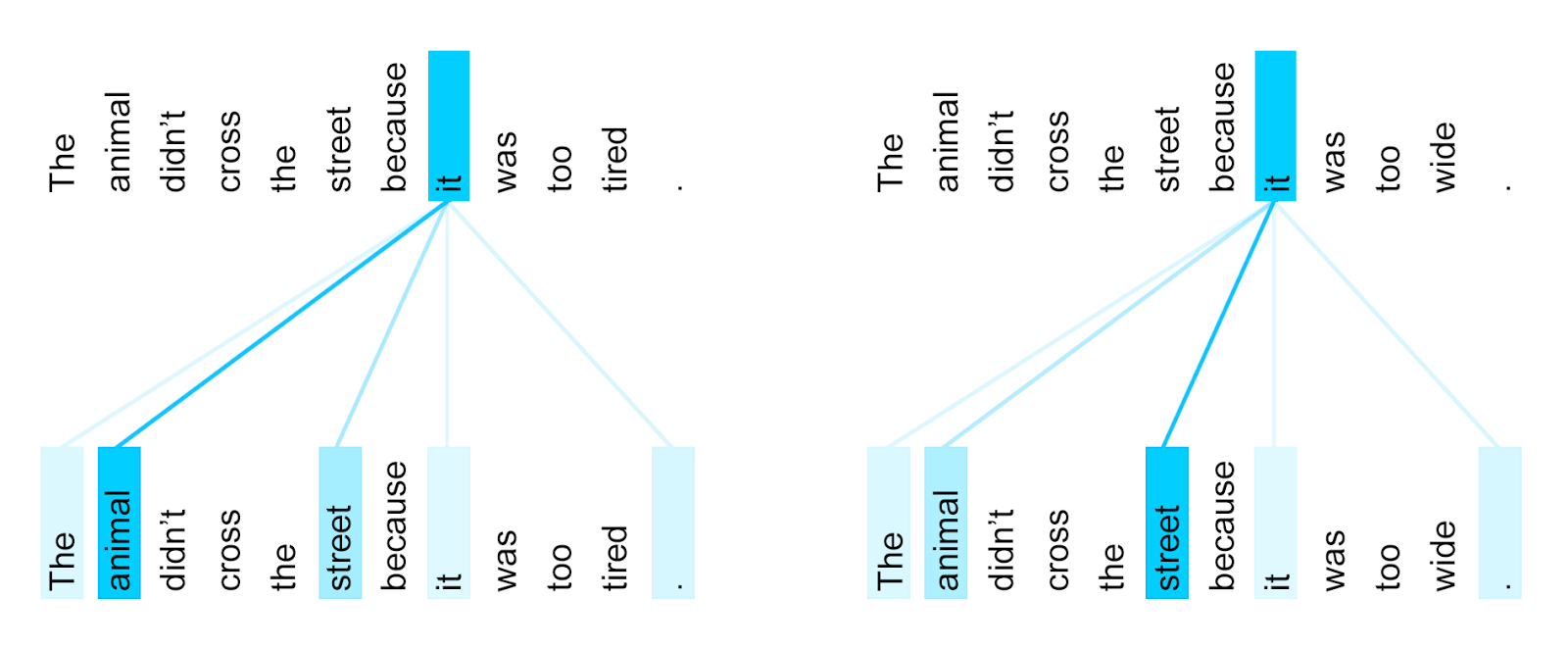
4. Attention Mechanism
- 정의: Attention 메커니즘은 모델이 입력 시퀀스의 다른 부분에 가변적으로 집중(주의)할 수 있게 하는 기법으로, 입력 시퀀스의 중요한 부분에 더 많은 가중치를 두어 처리하는 방식임.
- 개발 목적: Seq2Seq 모델의 고정된 길이 벡터 문제를 해결하고, 모델이 입력 시퀀스의 모든 부분에 대해 적절히 주의를 기울이면서 필요한 정보를 추출할 수 있도록 하기 위해 개발됨.
- 장점: 입력 시퀀스의 중요한 부분에 따라 가변적으로 주의를 기울일 수 있어, 모델의 성능과 해석 가능성을 향상시킬 수 있음.
- 단점: 모델의 복잡성과 계산 비용이 증가함.
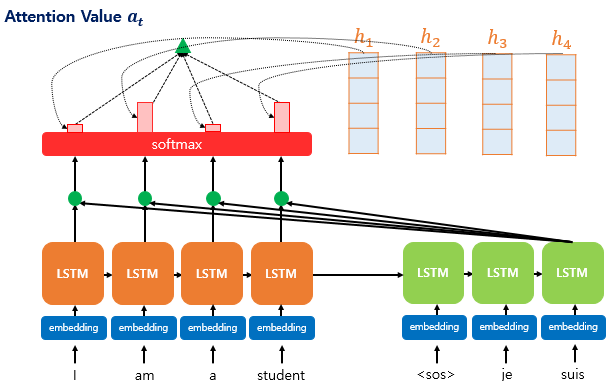
5. Transformer
- 정의: Transformer는 전적으로 Attention 메커니즘을 기반으로 하는 아키텍처로, 병렬 처리에 최적화되어 있으며, RNN이나 LSTM과 달리 시퀀스의 모든 부분을 동시에 처리할 수 있음.
- 개발 목적: 기존 RNN 기반 모델의 단점을 극복하고, 특히 자연어 처리 분야에서 대규모 데이터 세트를 보다 효율적으로 처리하기 위해 개발됨.
- 장점: 높은 병렬 처리 능력과 함께, Attention 메커니즘을 통해 시퀀스의 모든 부분에 대한 관계를 효과적으로 학습할 수 있음. 이로 인해 자연어 처리 분야에서 획기적인 성과를 달성함.
- 단점: 모델의 크기와 학습에 필요한 리소스가 매우 큼, 따라서 대규모 데이터 센터나 강력한 하드웨어 자원이 필요할 수 있음.

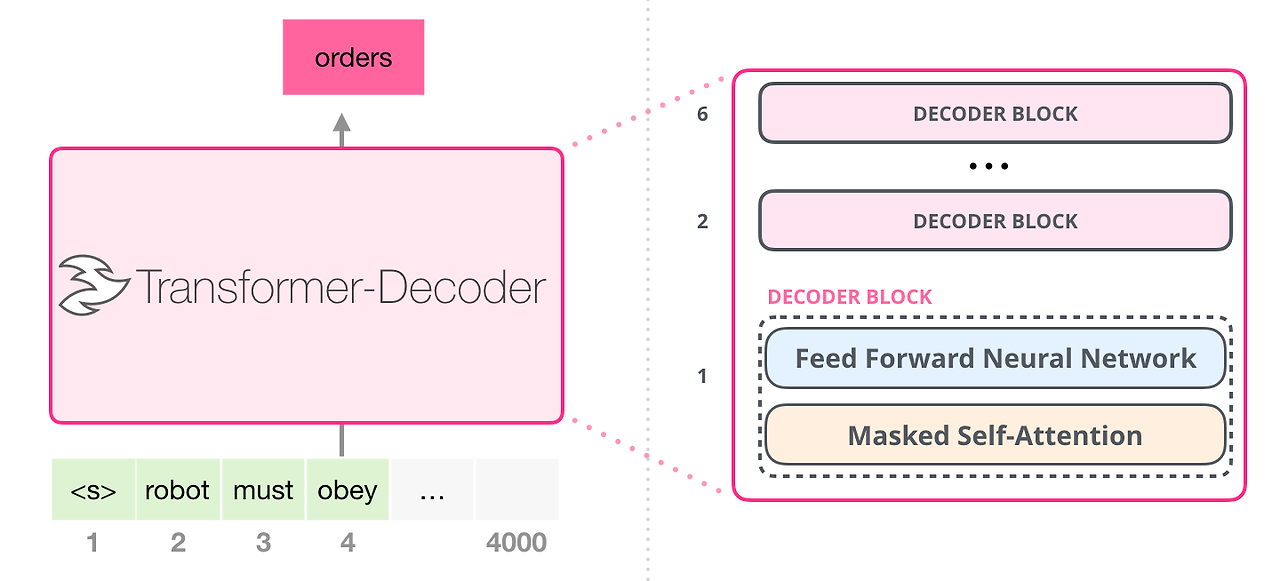
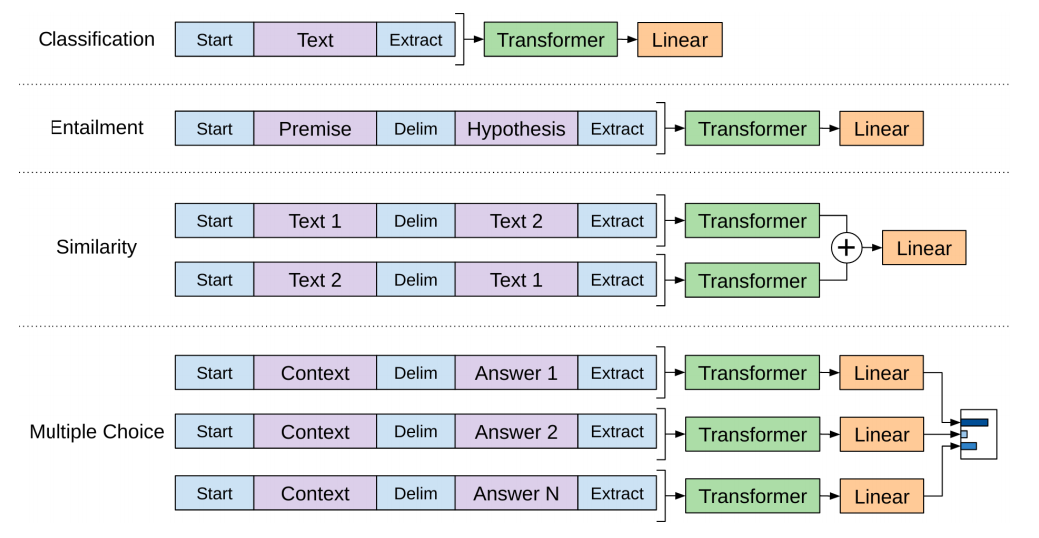
6. GPT-1 (Generative Pre-trained Transformer 1)
- 정의: GPT-1은 Transformer 아키텍처를 기반으로 하는 생성적 사전 훈련 모델로, 대규모 텍스트 데이터에서 언어 모델을 사전 훈련시키고, 이를 다양한 자연어 처리 작업에 적용할 수 있음.
- 개발 목적: 사전 훈련된 언어 모델을 통해, 별도의 태스크별 아키텍처 없이도 다양한 NLP 작업에 적용 가능한 범용성 있는 모델을 개발하기 위해 고안됨.
- 장점: 사전 훈련과 미세 조정을 통해 다양한 NLP 태스크에서 우수한 성능을 보임. 복잡한 아키텍처 변경 없이도 여러 작업에 적용 가능함.
- 단점: 큰 모델 크기와 높은 계산 비용. 초기 버전은 현재의 더 진보된 모델들에 비해 상대적으로 제한된 성능을 보임.
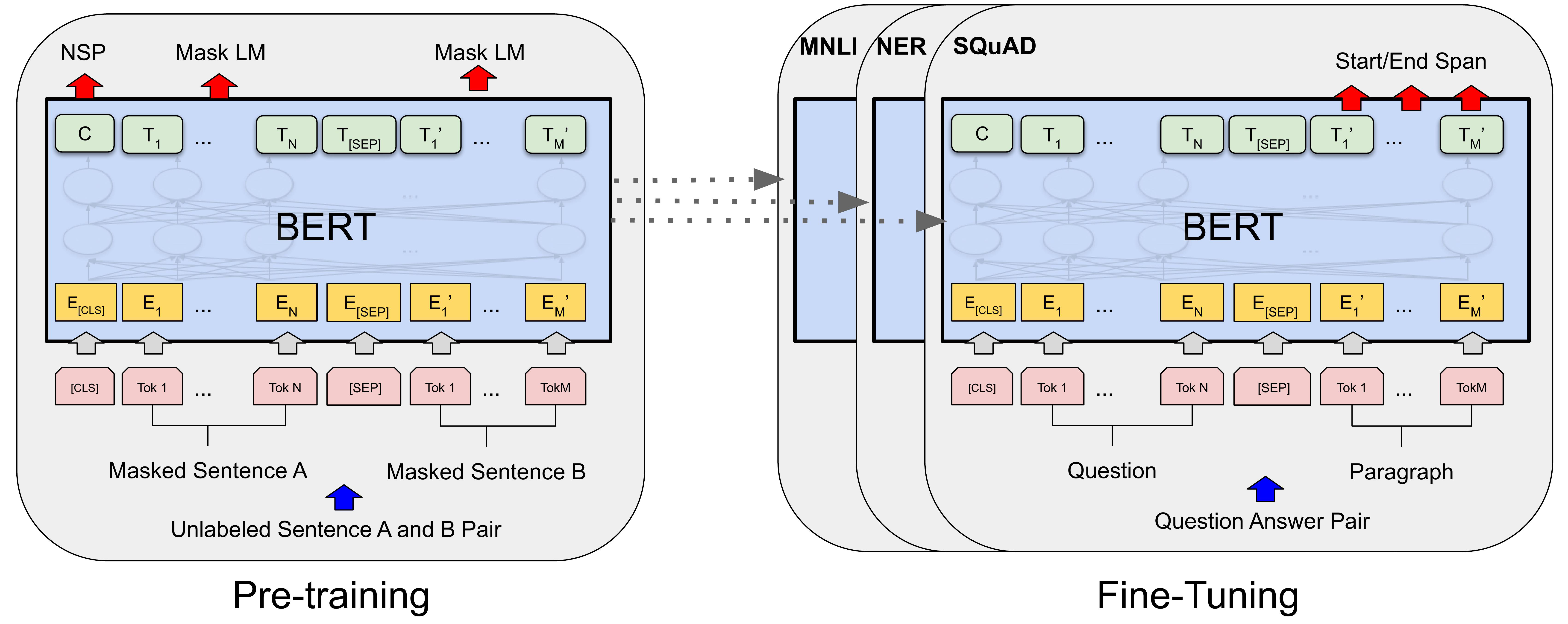
7. BERT (Bidirectional Encoder Representations from Transformers)
- 정의: BERT는 Transformer를 기반으로 하는 양방향 사전 훈련 언어 모델로, 텍스트의 양쪽 방향(좌, 우)에서의 문맥을 동시에 고려하여 텍스트의 의미를 이해함.
- 개발 목적: 텍스트의 양방향 문맥을 고려하여 보다 정교한 언어 이해를 가능하게 하고, 이를 통해 자연어 이해(NLU) 작업에서의 성능을 향상시키기 위해 개발됨.
- 장점: 양방향 문맥 이해를 통해 뛰어난 자연어 이해 능력을 보임. 다양한 NLU 작업에서 최첨단 성능을 달성함.
- 단점: 모델의 크기가 크고, 학습 및 추론 시 많은 계산 자원을 필요로 함.
8. GPT-3 (Generative Pre-trained Transformer 3)
- 정의: GPT-3은 GPT 시리즈 중 세 번째 모델로, Transformer 아키텍처를 기반으로 하며, 대규모 데이터셋을 사용해 사전 훈련된 언어 모델임.
- 개발 목적: 이전 버전의 GPT보다 훨씬 더 큰 데이터셋과 모델 크기를 사용하여, 자연어 처리에서의 생성적 및 이해 작업을 보다 향상시키기 위해 개발됨. 이를 통해 자연어 이해 및 생성 능력을 크게 향상시킬 수 있음을 목표로 함.
- 장점: 엄청난 규모의 데이터와 모델 크기 덕분에, 다양한 자연어 처리 작업에서 매우 높은 성능을 보임. 다양한 언어, 도메인, 작업에 걸쳐 범용적으로 사용 가능함.
- 단점: 매우 큰 모델 크기와 학습 및 추론에 필요한 계산 자원이 막대함. 이로 인해 사용과 연구에 상당한 비용이 발생할 수 있음.
9. GPT-4 (Generative Pre-trained Transformer 4)
- 정의: GPT-4는 GPT 시리즈의 네 번째 모델로, 이전 버전들보다 더 향상된 자연어 처리 능력과 범용성을 갖춘 대규모 사전 훈련 언어 모델임.
- 개발 목적: 자연어 이해 및 생성의 한계를 더욱 넓히고, 더 다양하고 복잡한 자연어 처리 작업을 처리할 수 있도록 설계됨. 더욱 정교한 문맥 이해와 더 넓은 범위의 지식 통합 능력을 목표로 함.
- 장점: 이전 모델들에 비해 더 향상된 성능과 범용성을 보임. 더 정교한 언어 이해 및 생성 능력을 바탕으로, 다양한 자연어 처리 작업에서 뛰어난 결과를 달성함.
- 단점: 역시나 모델 크기와 필요한 계산 자원이 큰 편이어서, 사용 및 연구에 있어서 상당한 비용이 들 수 있음.
10. RAG (Retrieval-Augmented Generation)
- 정의: RAG는 정보 검색을 통해 생성 과정을 강화한 언어 모델로, 대규모 데이터베이스에서 관련 정보를 검색하고, 이를 바탕으로 텍스트 생성을 수행함.
- 개발 목적: 단순한 텍스트 생성을 넘어서, 실제 세계의 지식과 정보를 반영한 더 정확하고 유용한 답변을 생성하기 위해 개발됨. 특히 지식 기반의 질의응답, 문서 요약 등의 태스크에 유용함.
- 장점: 실시간으로 대규모 정보원에서 데이터를 검색하여 답변의 정확도와 유용성을 높일 수 있음. 이를 통해 생성된 텍스트의 품질과 관련성이 크게 향상됨.
- 단점: 검색 과정이 추가되므로, 추론 시간이 길어지고 계산 비용이 증가할 수 있음. 또한, 효과적인 검색을 위해서는 대규모의 구조화된 지식 데이터베이스가 필요함.

[참고] 언어 모델의 발전 과정

"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
출처: https://link.coupang.com/a/bqpIFN
소문난 명강의 김기현의 자연어 처리 딥러닝 캠프: 파이토치 편:딥러닝 기반의 자연어 처리 기초
COUPANG
www.coupang.com
Reference:
https://paperswithcode.com/method/bert
https://paperswithcode.com/method/rag
https://yngie-c.github.io/nlp/2020/07/05/nlp_gpt/
https://blog.research.google/2017/08/transformer-novel-neural-network.html
https://medium.com/@navarai/the-architecture-of-a-basic-rnn-eb5ffe7f571e
https://medium.com/dovvie/deep-learning-long-short-term-memory-model-lstm-d4ee2f005973
반응형