
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- level 1
- ML Ops
- Level 2
- 통계학입문
- CS224W
- 인공지능
- MLOps
- SQLP
- Kubernetes
- LLM
- 자연어처리
- SQL
- 코딩테스트
- nlp
- gnn
- bigquery
- 포아송분포
- 데이터분석전문가
- 프로그래머스
- Ai
- 데이터분석준전문가
- 프레임워크
- SQLD
- RNN
- docker
- 통계방법론
- 머신러닝
- MYSQL
- ADsP
- 언어모델
- Today
- Total
코드 깎는 PM
[NLP 개론] #3 RAG(Retrieval-Augmented Generation)모델에 대해 알아보자 본문
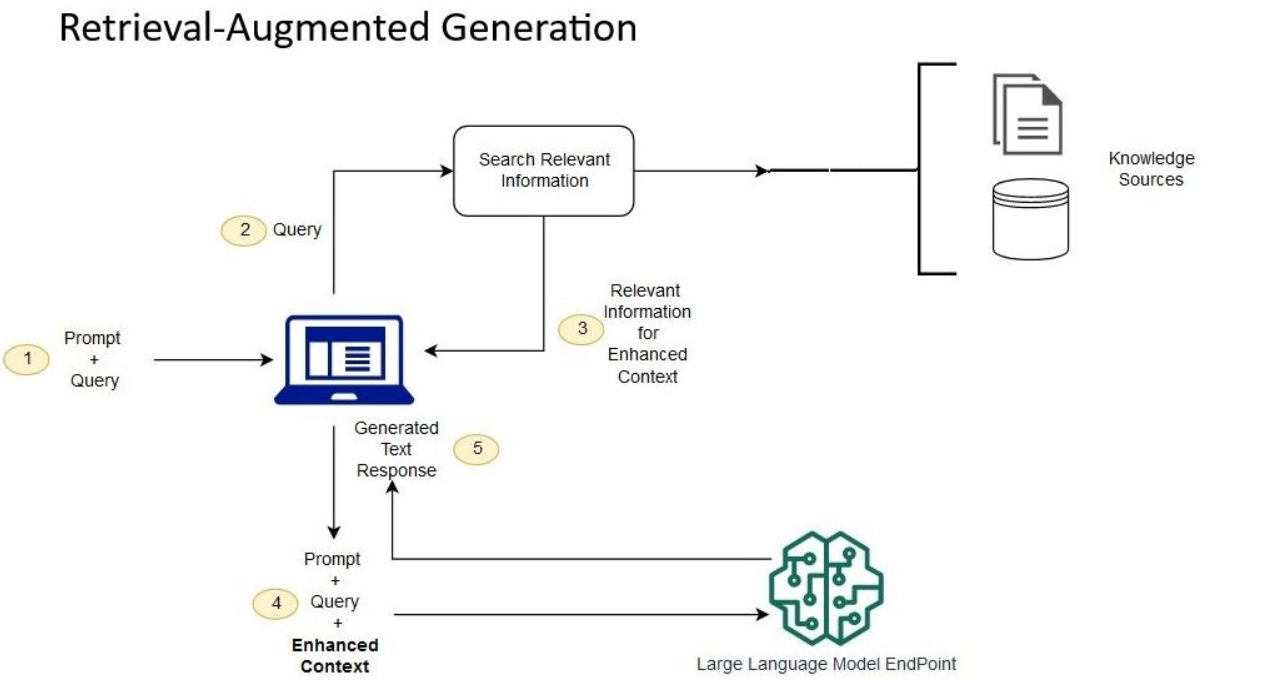
RAG(Retrieval-Augmented Generation) 모델은 자연어 처리(NLP)의 한 영역에서 중요한 역할을 하는, 정보 검색 기반의 생성 모델입니다. 이 모델은 기존의 생성 모델에 정보 검색 단계를 추가함으로써, 특정 질문에 대한 답변을 생성할 때 관련된 문서나 데이터를 참조할 수 있도록 설계되었습니다. RAG 모델의 핵심 아이디어는 텍스트 생성 과정에 외부 지식을 통합하는 것입니다. 이를 통해 모델은 더 정확하고 관련성 높은 답변을 생성할 수 있습니다.

RAG 모델의 구조
RAG 모델은 크게 두 부분으로 구성됩니다: **검색기(retriever)**와 생성기(generator).
- 검색기(retriever): 질문에 가장 관련이 깊은 문서나 데이터를 검색하는 역할을 합니다. 이 검색 과정은 일반적으로 미리 인덱싱된 문서 데이터베이스를 사용하여 수행됩니다. 검색 기능은 Dense Vector Retrieval(DVR) 방식을 사용하여 질문과 문서 간의 의미적 유사성을 기반으로 가장 관련 있는 문서를 찾아냅니다.
- 생성기(generator): 검색된 문서를 바탕으로 질문에 대한 답변을 생성합니다. 이 단계에서는 Transformer 기반의 언어 모델이 사용됩니다. 생성기는 질문과 검색된 문서의 정보를 결합하여 최종적인 답변을 생성합니다.
RAG 모델의 작동 원리
RAG 모델의 작동 원리는 다음과 같은 단계로 설명할 수 있습니다:
- 질문 인코딩: 사용자로부터 입력받은 질문을 벡터로 인코딩합니다.
- 문서 검색: 인코딩된 질문 벡터와 문서 데이터베이스 내의 문서 벡터들 사이의 유사도를 계산하여, 가장 유사한 상위 N개의 문서를 검색합니다.
- 답변 생성: 검색된 문서와 질문을 함께 생성기에 입력으로 제공하고, 생성기는 이 정보를 바탕으로 질문에 대한 답변을 생성합니다.
RAG 모델의 예시
예를 들어, 질문이 "파리의 주요 관광지는 무엇인가요?"라고 할 때, RAG 모델은 다음과 같이 작동합니다:
- 질문 인코딩: "파리의 주요 관광지는 무엇인가요?"를 벡터로 변환합니다.
- 문서 검색: 관련 문서 데이터베이스에서 "파리"와 "관광지"에 관련된 문서를 검색합니다. 예를 들어, 에펠탑, 루브르 박물관 등에 대한 문서를 찾을 수 있습니다.
- 답변 생성: 검색된 문서와 질문을 바탕으로, "파리의 주요 관광지로는 에펠탑, 루브르 박물관 등이 있습니다."와 같은 답변을 생성합니다.
수식과 함께 RAG 모델 설명
RAG 모델의 핵심 과정 중 하나는 검색된 문서와 질문을 바탕으로 답변을 생성하는 것입니다. 이 과정은 다음과 같은 수식으로 표현할 수 있습니다:
$$
P(\text{답변}|\text{질문}, \text{문서}) = \frac{1}{Z} \exp(\text{score}(\text{질문}, \text{문서})) \cdot P(\text{답변}|\text{질문}, \text{문서})
$$
여기서, $$\text{score}(\text{질문}, \text{문서})$$ 는 질문과 검색된 문서 간의 유사도 점수를 나타내며, 이 점수는 두 요소 간의 의미적 연관성을 반영합니다. $$P(\text{답변}|\text{질문}, \text{문서})$$ 는 주어진 질문과 문서에 대한 답변의 확률을 나타냅니다. $$Z$$ 는 정규화 상수로, 모든 가능한 답변에 대한 확률의 합이 1이 되도록 조정합니다.
이 수식은 RAG 모델이 어떻게 질문과 관련된 문서를 활용하여 보다 정확한 답변을 생성하는지를 수학적으로 설명해 줍니다. 질문과 문서 간의 유사도가 높을수록, 해당 문서가 답변 생성에 더 큰 영향을 미치게 됩니다. 이를 통해 RAG 모델은 질문에 가장 관련된 정보를 바탕으로 답변을 생성할 수 있게 됩니다.
RAG 모델 예시 코드 및 결과 설명
RAG 모델을 사용하는 구체적인 예시는 Hugging Face의 Transformers 라이브러리를 통해 쉽게 구현할 수 있습니다. 이 예시에서는 질문에 대한 답변을 생성하는 간단한 프로세스를 보여줍니다.
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
import torch
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
question = "What is the capital of France?"
inputs = tokenizer(question, return_tensors="pt")
with torch.no_grad():
generated_ids = model.generate(input_ids=inputs["input_ids"])
answer = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(answer)위 코드는 "What is the capital of France?"라는 질문에 대한 답변을 생성합니다. 여기서 RAG 모델은 관련된 문서를 검색하고, 이를 바탕으로 질문에 대한 답변을 생성하는 과정을 거칩니다. 결과적으로 모델은 "Paris"라는 정확한 답변을 생성할 수 있습니다.
이미지 분야와의 협업
RAG 모델과 같은 자연어 처리 기술은 이미지 분야와의 협업을 통해 더욱 풍부한 정보 처리와 상호작용을 가능하게 합니다. 예를 들어, 이미지 캡셔닝(image captioning)에서 RAG 모델은 이미지에 대한 설명을 생성하기 위해 외부 지식을 검색하고 참조할 수 있습니다. 이러한 접근 방식은 이미지의 내용을 더 정확하게 이해하고, 관련성 높은 설명을 생성하는 데 도움이 됩니다.
또한, 시각적 질문 응답(Visual Question Answering, VQA)에서도 RAG 모델은 중요한 역할을 할 수 있습니다. 모델은 주어진 이미지와 관련된 질문에 답하기 위해 필요한 정보를 검색하고, 이를 바탕으로 보다 정확한 답변을 생성할 수 있습니다.
상용화 현황
RAG 모델과 같은 첨단 기술은 이미 여러 분야에서 상용화되고 있습니다. 예를 들어, 검색 엔진, 챗봇, 추천 시스템 등에서는 사용자의 질문이나 요구에 맞는 정보를 제공하기 위해 RAG 모델을 활용할 수 있습니다. 이러한 시스템은 사용자 경험을 개선하고, 보다 관련성 높은 정보를 신속하게 제공하는 데 기여합니다.
또한, 교육 분야에서는 RAG 모델을 활용하여 학습 자료에서 필요한 정보를 검색하고, 맞춤형 학습 콘텐츠를 생성하는 데 활용됩니다. 이를 통해 학습자에게 개인화된 학습 경험을 제공할 수 있습니다.
상업적인 관점에서는, 기업들이 자체 데이터를 활용하여 RAG 모델을 훈련시키고, 이를 통해 고객 서비스, 마케팅, 제품 개발 등 다양한 영역에서의 응용 프로그램을 개발하고 있습니다.
결론
RAG 모델은 정보 검색과 텍스트 생성을 결합하여, 복잡한 질문에 대한 정확하고 관련성 높은 답변을 생성할 수 있는 강력한 도구입니다. 이미지 분야와의 협업을 통해, 자연어 처리와 컴퓨터 비전의 경계를 허물고, 보다 진보된 인공지능 응용 프로그램의 개발을 가능하게 합니다. 상용화 측면에서는 다양한 산업에서 RAG 모델을 활용한 혁신적인 서비스와 제품이 등장하고 있으며, 이는 앞으로도 계속될 전망입니다.
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
출처: https://link.coupang.com/a/bqpIFN
소문난 명강의 김기현의 자연어 처리 딥러닝 캠프: 파이토치 편:딥러닝 기반의 자연어 처리 기초
COUPANG
www.coupang.com
출처
RAG 모델에 관한 자세한 내용은 다음 출처에서 확인할 수 있습니다:
- Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." In Proceedings of NeurIPS 2020.
이 문서는 RAG 모델의 개념을 소개하고, 모델이 어떻게 다양한 NLP 태스크에서 사용될 수 있는지에 대한 심층적인 분석을 제공합니다.
Reference: